Open Source Social Media Protocol from Bluesky
A Self-Authenticating Social Protocol
Self-authenticated data moves the authority to the user. This data is inherently live - that is, canonical and transactable - no matter where it is located. The Web is connection-centric. That means, when your content is not hosted anywhere anymore it becomes dead.
The three components that enable self-authentication are cryptographic identifiers, content-addressed data, and verifiable computation.
Most important objectives are portability, scale and trust.
Portability
Portability is the ability to move between services without losing everything. Now when you want to switch from X to Threads you lose all your posts and your social graph. That is even the case with other federated protocols like ActivityPub and Matrix. Self-authenticating protocols allow to switch providers because the authority lies within the data and not within the host.
Scale
Social networking platforms bring hundred of millions of people together in a global conversation. For this special infrastructure is needed. The challenge is to combine decentralization with scale and keep a global view across the network. Self-authenticating data enable store-and-forward caches. Aggregators can host data on behalf of smaller providers without reducing trust in the data’s authenticity.
Trust
The algorithms and moderation rules of social media platforms are intransparent. Especially since Elon Musk bought Twitter and turned it into a right wing propaganda machine, but also other networks like Facebook are full of biases and often enough just try to engage their users through polarization. AT Protocol tries to build around trust by exposing what’s going on under the hood and allowing users to adjust their experience. Self-authenticated data can retain metadata, like publisher or changes. Verifiable computation provides new tools for establishing trust by showing precisely how the results were produced.
Federation Architecture Overview
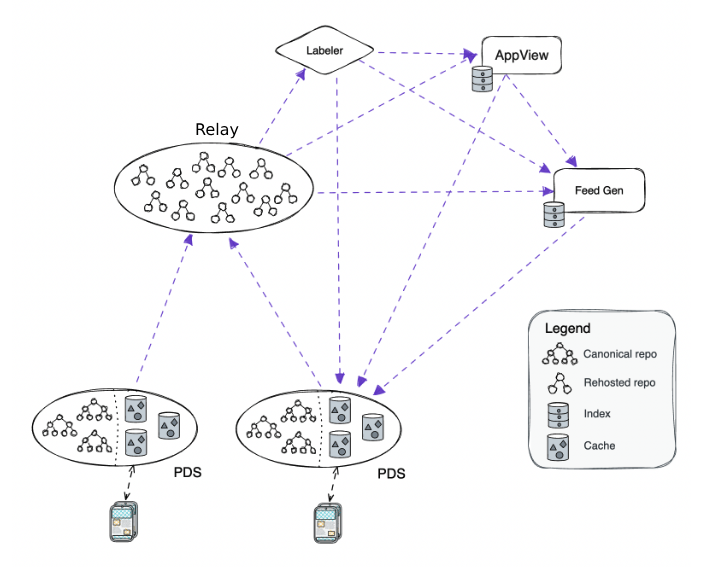 The three main services of our first federation are personal data servers (PDS), relays, and App Views. Developers can also run feed generators (custom feeds), and labelers are in active development.
The three main services of our first federation are personal data servers (PDS), relays, and App Views. Developers can also run feed generators (custom feeds), and labelers are in active development.
- Personal Data Server (PDS)
- A PDS acts as the participant’s agent in the network. This is what hosts your data (like the posts you’ve created) in your repo. It also handles your account & login, manages your repo’s signing key, stores any of your private data (like which accounts you have muted), and handles the services you talk to for any request.
- Relay
- The Relay handles “big-world” networking. It crawls the network, gathering as much data as it can, and outputs it in one big stream for other services to use. It’s analogous to a firehose provider or a super-powered relay node.
- App Views
- An App View is the piece that actually assembles your feed and all the other data you see in the app, and is generally expected to be downstream from a Relay’s firehose of data. This is a highly semantically-aware service that produces aggregations across the network and views over some subset of the network. This is analogous to a prism that takes in the Relay’s raw firehose of data from the network, and outputs views that enable an app to show a curated feed to a user. For example, the Relay might crawl to grab data such as a certain post’s likes and reposts, and the app view will output the count of those metrics.